עד עכשיו, אתה מודע לעובדה שהגלקסי S24הקו הוא מה שהביאגלקסי AI: קבוצת התכונות האינטליגנטיות באופן מלאכותי שהדהימו את העולם עם Circle to Search, Live Translate ועוד. Galaxy AI גם גרמה לאפל להתעשת ולהתקדם (קצת) בתחום הבינה המלאכותית עם הקרובים שלהםApple Intelligence.
אחת התכונות המרשימות ביותר של Galaxy AI היא Live Translate - זה ממש שומע את מה שהדובר אומר ואז מתרגם את זה לשפת ההעדפה שלך. התכונה הגיעה עם 13 שפות נתמכות ולאחרונה נוספו שלוש שפות נוספות, בסך הכל 16.
לא פעם תהיתי איך דבר כזה מתאפשר - בטח היה קשה מאוד לתכנן ולפתח אותו! סמסונג מאשרת את הניחוש שלי עם האחרון שלהמאמר מפורטעל Galaxy AI ועל הניסיונות והקשיים של הצוותים ברחבי העולם מאחורי הפרויקט.
תכונות Galaxy AI כגון Live Translate מבצעות שלושה תהליכי ליבה: זיהוי דיבור אוטומטי (ASR), תרגום מכונה עצבית (NMT) וטקסט לדיבור (TTS).
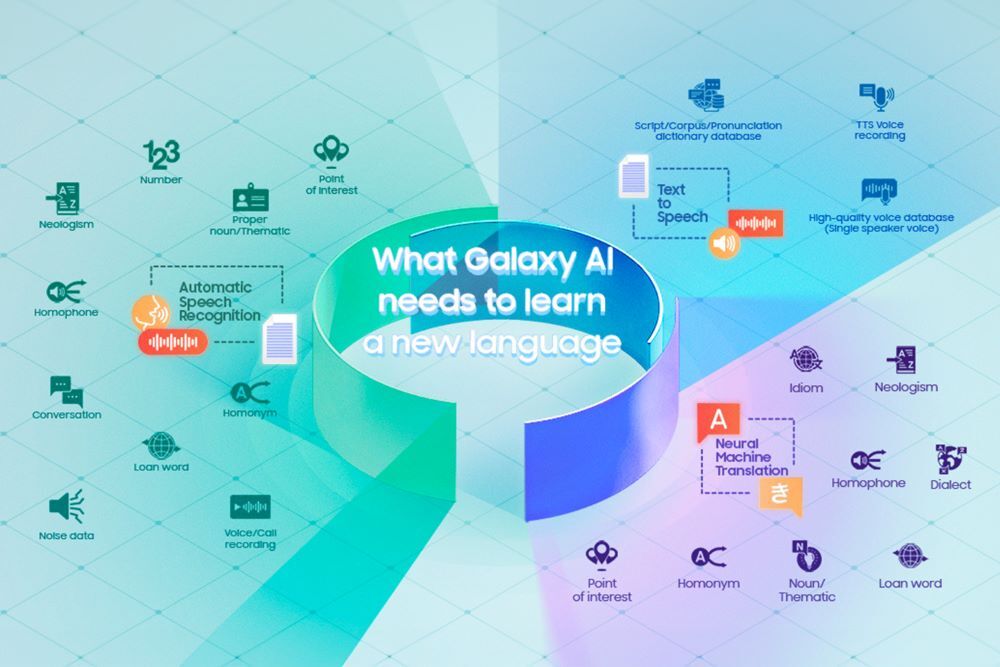
זיהוי דיבור אוטומטי (ASR), תרגום מכונה עצבית (NMT) וטקסט לדיבור (TTS) דורשים כל אחד סטים נפרדים של מידע לאימון. | קרדיט תמונה – סמסונג
איך פותרים את אתגר הדיאלקטים?
עד כאן, כל כך טוב: זיהוי הדיבור עושה את זה, ואז התרגום של המכונה העצבית נכנס, ואז הדיבור המתורגם נפלט אליך בחזרה באמצעות טקסט לדיבור.
אבל מה עושים כשהדיאלקטים נכנסים לטבעת!?
לדוגמה, מכון המחקר והפיתוח של סמסונג וייטנאם (SRV) התמודד עם מכשולים עם מודלים של זיהוי דיבור אוטומטי בגללוייטנאמית היא שפה בעלת שישה גוונים ברורים. שפות טונאליות יכולות להיות קשה לזיהוי הבינה המלאכותית בגלל המורכבות שהגוונים מוסיפים לניואנסים הלשוניים. הצוות נענה לאתגר עם מודל המבדיל בין פריימים קצרים יותר של שמע20 מילישניות.
לאחר מכן, למכון המחקר והפיתוח של סמסונג בפולין הייתה "המשוכה האדירה" של אימון מודלים של תרגום מכונות עצביות עבור יבשת מגוונת כמו אירופה. בהסתמך על הניסיון הרב שלה עם פרויקטים בלמעלה מ-30 שפות בארבעה אזורי זמן, הצוות הפולני ניווט בהצלחה את האתגרים של ביטויים בלתי ניתנים לתרגום וניהל ביטויים אידיומטיים חסרי מקבילות ישירות בשפות אחרות.
גם למכון המחקר והפיתוח של סמסונג מירדן לא היה קל להתאים את הערבית - שפה המדוברת ביותר מ-20 מדינות בכ-30 ניבים - ל-Galaxy AI.
יצירת מודל טקסט לדיבור הייתה מאמץ לא קטן, שכן דיאקריטיות ומדריכים להגייה מובנים באופן נרחב על ידי דוברי ערבית שפת אם, אךנעדר בכתב. באמצעות מודל חיזוי מתוחכם לזיהוי דיאקריטים חסרים, הצוות פרסם בהצלחה מודל שפה המסוגל להבין ניבים ולהגיב בערבית תקנית.
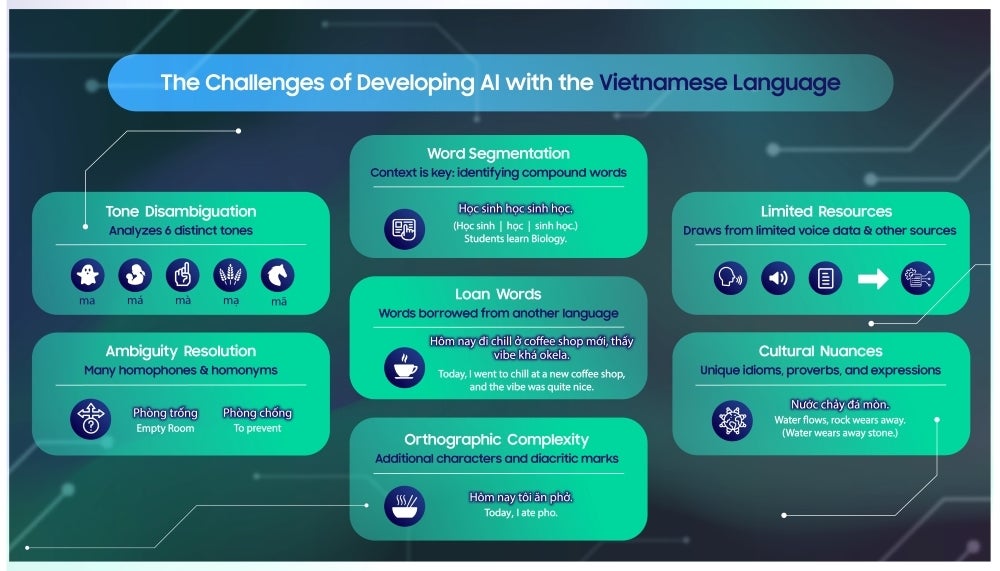
לכל שפה יש קבוצה נפרדת של תכונות שמציבות אתגרים ביצירת מודל שפת בינה מלאכותית עבורה. גוונים מוסיפים למורכבות עבור שפות טונאליות כמו וייטנאמית. | קרדיט תמונה – סמסונג
מכון המחקר והפיתוח של סמסונג הודו-בנגלור חבר עם המכון הטכנולוגי Vellore כדי לאסוף כמעט מיליון שורות של נתוני אודיו מפולחים ואצורים, הכוללים דיבור, מילים ופקודות שיחה. שיתוף הפעולה הזה סיפק לסטודנטים ניסיון מעשי בפרויקט אמיתי והנחיה של מומחי סמסונג. איסוף הנתונים הנרחב איפשר ל-SRI-B לאמן את Galaxy AI בהינדית, המכסה למעלה מ-20 ניבים אזוריים יחד עם הטיות הטונאליות הייחודיות שלהם, סימני הפיסוק והדיבוריות.
תובנות לשוניות מקומיות היו קריטיות לפיתוח המודל הספרדי של אמריקה הלטינית, ששיקפו את מגוון השפה ואת בסיס המשתמשים המגוון שלה. לדוגמה, המילה ל"בריכת שחייה" משתנה אזורית, והיא "אלברקה" במקסיקו, "פיסצ'ינה" בקולומביה, בוליביה וונצואלה ו"פילטה" בארגנטינה, פרגוואי ואורוגוואי.
בינתיים, מכון המחקר והפיתוח של סמסונג סין-בייג'ינג ומכון המחקר והפיתוח של סמסונג סין-גואנגג'ואו שיתפו פעולה עם החברות הסיניות Baidu ו-Meitu. הם מינפו את הניסיון שלהם עם מודלים של שפה גדולים, כגון ERNIE Bot ו- MiracleVision, בהתאמה. כתוצאה מכך, Galaxy AI תומך כעת הן בסינית מנדרינית והן בקנטונזית, ומתאים למצבים העיקריים של שפות אלו.
נעשה שימוש גם בשיחות מבתי קפה
בהאסה אינדונזיה ידועה בשימוש הנרחב שלה במשמעויות הקשריות ומרומזות, התלויות לרוב ברמזים חברתיים ומצביים. כדי להתמודד עם זה, חוקרים ממכון המחקר והפיתוח של סמסונג באינדונזיה ערכו הקלטות שטח בבתי קפה ובסביבות עבודה, תוך צילוםרעשי סביבה אותנטייםשעלול לעוות את הקלט. זה עזר למודל ללמוד לחלץ מידע חיוני מקלט מילולי, ובכך לשפר את הדיוק של זיהוי דיבור.
ליפנית, עם מספר הצלילים המצומצם שלה, יש הרבה מילים הומוניות שיש לפרש בהתבסס על הקשר. כדי להתמודד עם האתגר הזה, מכון המחקר והפיתוח של סמסונג ביפן השתמש ב-Samsung Gauss, מודל השפה הגדול הפנימי של החברה, כדי ליצור משפטים הקשריים עם מילים וביטויים רלוונטיים לתרחישים. גישה זו עזרה למודל הבינה המלאכותית להבחין ביעילות בין מילים הומוניות שונות.
הומוניים הן מילים בעלות משמעויות שונות שהן הומוגרפיות (מילים בעלות אותו איות) או הומפונים (מילים בעלות אותה הגייה), או שניהם.
AI הוא באמת מורכב - ואני אפילו לא יכול לדמיין מה צופן העתיד בתחום הספציפי הזה.
